세레모니(CereMony)는 스튜디오, 카메라 없이
만드는 생성형 영상 AI 플랫폼입니다.
-
01

운영 효율성 향상
-
02

고객 경험 향상
-
03

24시간 대응 가능
-
04

콘텐츠 자동화
세레모니(CereMony)
서비스 이용 방법
How to Use
How to Use
How to Use
How to Use
How to Use
How to Use
How to Use
How to Use
How to Use
How to Use
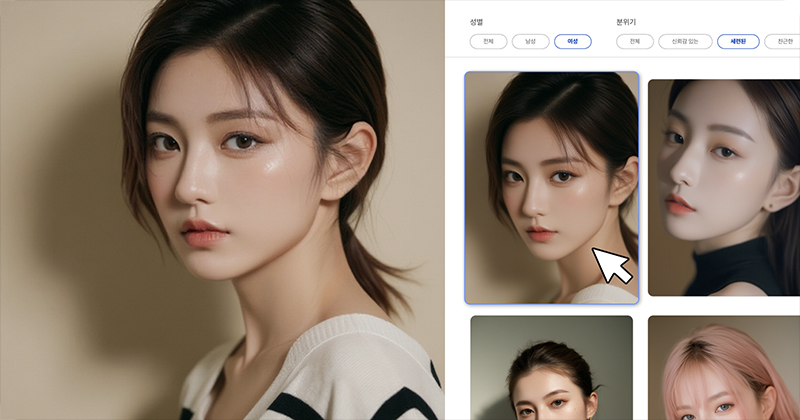
AI 아바타를 선택합니다.
영상의 주제에 맞춰 AI 아바타를 선택할 수 있습니다. 아바타의 의상, 스튜디오 배경 등을 원하는 대로 설정하여 원하는 콘셉트에 맞게 구성할 수 있습니다.

스크립트를 입력합니다.
아바타가 말할 내용을 스크립트로 작성합니다. 제품 광고, 안내 사항 등 다양한 내용을 입력할 수 있으며, 언어를 선택하여 글로벌 콘텐츠를 제작하는 것도 가능합니다.

생성된 영상을 편집합니다.
스크립트를 입력하면 AI가 자동으로 영상을 생성합니다. 생성된 영상에 자막, 다양한 효과 등을 추가하여 완성도를 높일 수 있습니다.
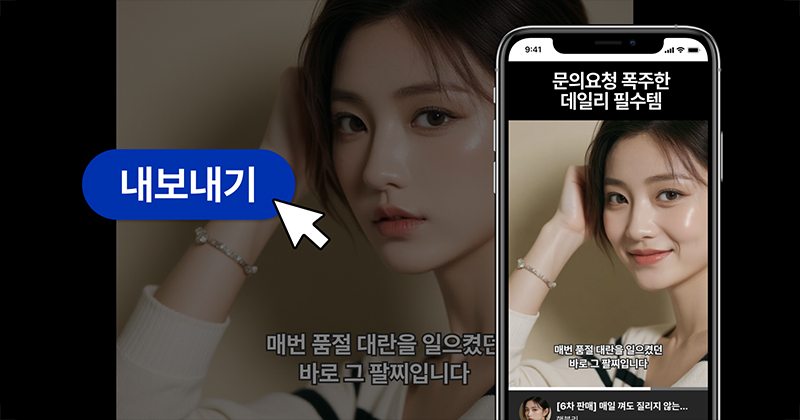
저장하고 공유합니다.
공유하려는 플랫폼에 맞게 영상 길이와 파일 확장자를 선택하여 영상을 저장합니다.
기존 방식을 단축하여 리스크를 절감합니다.
상업적 이용 가능
초상권 · 저작권 문제 없는
인공지능 호스트
제작 비용, 시간 절약
스튜디오 & 촬영 장비 대여비,
특수 효과, 음악 등의 비용 감소
24시간 생성 가능
시간·장소에 제약을 받지 않고
온라인으로 영상 생성
인공지능을 활용하여
고품질 영상을 제작합니다.
데이터 수집 및 정제
유효성 검사
이미지 모델링
데이터 학습
반복학습
시나리오 작성
영상/사진 변환
데이터 필독
• 데이터 수집 시, 초상권 및 저작권, 특별 제품의 이미지 제거
• 부족 데이터는 생성을 통해 법적 분쟁 사전에 제거
모델 성능/능력 보장 필수
• 데이터 분할 (학습, 검증,테스트)
• 데이터의 대표성 및 다양성
• 성능 지표의 선정
• 교차 검증 활용
• 오버피팅 및 언더피팅 확인
AI 쇼 호스트 3D 모델링 및 애니메이션 제작
VAE (Variational Autoencoder) 및
TTS (Text-to-Speech) 기술 적용
홍보 스크립트 작성
• AI 쇼 호스트가 진행할 뉴스,
광고, 제품 등
• 자동 대본 적용 및
자연스러운 음성 톤 설정 등
영상 및 사진 콘텐츠 생성
• 최종 AI 쇼 호스트의 콘텐츠 생성
• 라이브 방송, 광고,
홍보 콘텐츠 제작 및 최적화
데이터 수집 및 정제
유효성 검사
데이터 필독
• 데이터 수집 시, 초상권 및 저작권, 특별 제품의 이미지 제거
• 부족 데이터는 생성을 통해 법적 분쟁 사전에 제거
모델 성능/능력 보장 필수
• 데이터 분할 (학습, 검증,테스트)
• 데이터의 대표성 및 다양성
• 성능 지표의 선정
• 교차 검증 활용
• 오버피팅 및 언더피팅 확인
이미지 모델링
데이터 학습
AI 쇼 호스트 3D 모델링 및 애니메이션 제작
VAE (Variational Autoencoder) 및
TTs (Text-to-Speech) 기술 적용
시나리오 작성
영상/사진 변환
홍보 스크립트 작성
• AI 쇼 호스트가 진행할 뉴스,
광고, 제품 등
• 자동 대본 적용 및
자연스러운 음성 톤 설정 등
영상 및 사진 콘텐츠 생성
• 최종 AI 쇼 호스트의 콘텐츠 생성
• 라이브 방송, 광고,
홍보 콘텐츠 제작 및 최적화



생성이미지

Encoder

Diffusion Process
Timestep t
N x DiT Blocks
Cross
Attention
UMT5
Decoder

Model
Dimension
Input Dimension
Output Dimesion
Feedforward
Dimension
Frequency
Dimension
Number of
Heads
Number of
Layers
1.3B
1536
16
16
8960
256
12
30
14B
5120
16
16
13824
256
40
40
Feedforward
Dimension
Frequency
Dimension
Number of
Heads
Number of
Layers
8960
256
12
30
13824
256
40
40
염색된 머리카락에도
물 빠짐이 없는 삼푸
텍스트

이미지
음성
Detector
Model

Text Encoder

Variational
Auto Encoder

Text to
Video Model
Image to
Video Model
Clip Vision
Lip Syncing
Generator

영상
어떤 분야에도 유연하게
적용할 수 있습니다.

쇼 호스트
상품 또는 서비스를 AI 호스트가 홍보합니다.

안내 영상
사업/행사 또는프로그램 등을 안내할 수 있습니다.

교육 컨텐츠
온라인 강의, 온보딩 영상을 제작할 수 있습니다.

AI 아바타
유튜브, 인스타, 틱톡 등에 업로드할 콘텐츠를 제작할 수 있습니다.
쇼 호스트
상품 또는 서비스를 AI 호스트가 홍보합니다.
안내 영상
사업/행사 또는프로그램 등을 안내할 수 있습니다.
교육 컨텐츠
온라인 강의, 온보딩 영상을 제작할 수 있습니다.
AI 아바타
유튜브, 인스타, 틱톡 등에 업로드할 콘텐츠를 제작할 수 있습니다.
세레모니가 더 궁금하신가요?